Le module MultiProcessing¶
Python propose un module nommé multiprocessing qui supporte les multi-processus via une API similaire au module de threading. Le module permet de générer véritablement des sous-processus au lieu de threads, et donc, une meilleure parallélisation. Ces processus:
fonctionnent de façon indépendante;
ont leur propre espace mémoire.
De ce fait, le module multiprocessing permet au programmeur d’exploiter pleinement plusieurs processeurs sur une machine donnée. Il fonctionne sous Unix et Windows.
Class Process¶
Dans le multi-traitement, les processus sont générés en créant un objet Process et en appelant sa méthode start(). Le processus suit l’API de threading.thread. Un exemple trivial d’un programme multiprocessus:
- ::
>>> # -*coding: UTF-8 -*- >>> from multiprocessing import Process >>> >>> def f(name): >>> print 'hello', name >>> >>> if __name__ == '__main__': >>> p = Process(target=f, args=('bob',)) >>> p.start() >>> p.join()
Notons les arguments suivants:
target: définit une fonction qui est appelée par la méthode run();
args: tuple d’arguments passé à la fonction lors du lancement de la méthode.
Les principales méthodes de la classe Processing à retenir sont listées ci-dessous.
start()
Start() permet de lancer un nouveau processus et d’y exécuter la méthode run().
run()
Méthode exécutée dans le thread. Si target a été défini, run() l’exécute. Run() peut aussi être surchargée pour contenir directement le code à exécuter. Le processus est alive dès que cette méthode est appelée. Lorsque run() est terminée, soit par la fin de l’exécution, soit par une levée d’exception, le processus est dit dead.
join([timeout])
Attend que le processus se termine. Cette méthode peut être appelée par un autre processus qui se met alors en attente de la fin d’exécution du processus principal. Si timeout est fourni, c’est un réel qui détermine en seconde le temps d’attente maximum. Passé ce délai, le processus en attente est débloqué.
is_alive()
Informe sur l’état du processus. Renvoie True si la méthode run() est en cours d’exécution.
Exemples de premiers process¶
- ::
>>> # -*coding: UTF-8 -*- >>> from multiprocessing import Pool, Process >>> from time import sleep >>> def print_name(name): >>> sleep(3) >>> print 'hello', name >>> >>> >>> if __name__ == '__main__': >>> #création d'un premier processus >>> p = Process(target=print_name, args=('bob',)) >>> p.start() >>> p2 = Process(target=print_name, args=('bill',)) >>> p2.start() >>> while p.is_alive() or p2.is_alive(): >>> print 'attente print' >>> sleep(1)
Lorsque le code est plus complexe qu’une simple fonction, il peut être judicieux de le regrouper dans une classe dérivée de Process et de surcharger run(), voire __init__ si nécessaire.
Excercice¶
Calculer le carré d’une séquence constituée de N listes d’entiers (obtenues façon aléatoire). Mettre les résultats dans une nouvelle séquence. Deux techniques:
Approche séquentielle via une boucle
Approche par Process
Vérifier le temps total d’exécution pour chaque approche. Quelle est la plus rapide ?
Partager¶
Considérons le programme suivant pour comprendre notre problématique :
- ::
>>> # -*coding: UTF-8 -*- >>> import multiprocessing >>> >>> # empty list with global scope >>> result = [] >>> >>> def square_list(mylist): >>> """ >>> function to square a given list >>> """ >>> global result >>> # append squares of mylist to global list result >>> for num in mylist: >>> result.append(num * num) >>> # print global list result >>> print("Result(in process p1): {}".format(result)) >>> >>> if __name__ == "__main__": >>> # input list >>> mylist = [1,2,3,4] >>> >>> # creating new process >>> p1 = multiprocessing.Process(target=square_list, args=(mylist,)) >>> # starting process >>> p1.start() >>> # wait until process is finished >>> p1.join() >>> >>> # print global result list >>> print("Result(in main program): {}".format(result))
Dans l’exemple ci-dessus, nous essayons d’imprimer le contenu de la liste globale des résultats à deux endroits :
dans la fonction square_list. Comme cette fonction est appelée par le processus p1, la liste des résultats est modifiée uniquement dans l’espace mémoire du processus p1;
après l’achèvement du processus p1 dans le programme principal. Comme le programme principal est exécuté par un processus différent, son espace mémoire contient toujours la liste des résultats vides.
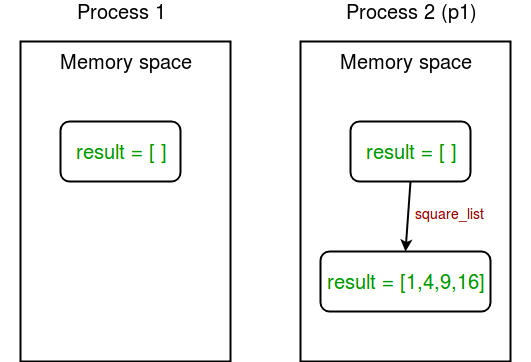
Comme résoudre l’énigme ?
Mémoire partagée¶
Le module multiprocesseur fournit des objets Array et Value pour partager les données entre les processus:
Array: un tableau ctypes alloué à partir de la mémoire partagée;
Valeur: un objet ctypes alloué à partir de la mémoire partagée.
Vous trouverez ci-dessous un exemple simple montrant l’utilisation de Array et Value pour le partage de données entre les processus.
- ::
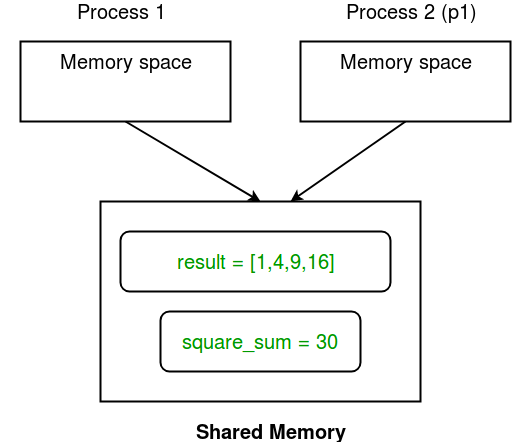
>>> # -*coding: UTF-8 -*- >>> import multiprocessing >>> >>> def square_list(mylist, result, square_sum): >>> """ >>> function to square a given list >>> """ >>> # append squares of mylist to result array >>> for idx, num in enumerate(mylist): >>> result[idx] = num * num >>> >>> # square_sum value >>> square_sum.value = sum(result) >>> >>> # print result Array >>> print("Result(in process p1): {}".format(result[:])) >>> >>> # print square_sum Value >>> print("Sum of squares(in process p1): {}".format(square_sum.value)) >>> >>> if __name__ == "__main__": >>> # input list >>> mylist = [1,2,3,4] >>> >>> # creating Array of int data type with space for 4 integers >>> result = multiprocessing.Array('i', 4) >>> >>> # creating Value of int data type >>> square_sum = multiprocessing.Value('i') >>> >>> # creating new process >>> p1 = multiprocessing.Process(target=square_list, args=(mylist, result, square_sum)) >>> >>> # starting process >>> p1.start() >>> >>> # wait until process is finished >>> p1.join() >>> >>> # print result array >>> print("Result(in main program): {}".format(result[:])) >>> >>> # print square_sum Value >>> print("Sum of squares(in main program): {}".format(square_sum.value))
Essayons de comprendre le code ci-dessus ligne par ligne :
Tout d’abord, nous créons un résultat de tableau comme ceci :
>>> result = multiprocessing.Array('i', 4)
Le premier argument est le type de données. i représente un nombre entier tandis que “d” représente le type de données flottantes. Le deuxième argument est la taille du tableau. Ici, nous créons un tableau de 4 éléments. De même, nous créons un objet Value nommé square_sum comme ceci :
>>> square_sum = multiprocessing.Value('i')
Ici, il suffit de spécifier le type de données. La valeur peut se voir attribuer une valeur initiale (disons 10) comme ceci :
>>> square_sum = multiprocessing.Value('i', 10)
Deuxièmement, nous passons result et square_sum comme arguments lors de la création de l’objet Process.
>>> p1 = multiprocessing.Process(target=square_list, args=(mylist, result, result, square_sum)))
Les éléments de tableau de résultats reçoivent une valeur en spécifiant l’index de l’élément de tableau.
>>> for idx, num dans enumerate(mylist) :
>>> result[idx] = num * num num * num
square_sum reçoit une valeur en utilisant son attribut value :
>>> square_sum.value = somme(result)
Afin d’imprimer les éléments du tableau de résultats, nous utilisons result[:] pour imprimer le tableau complet.
>>> print("Result(in process p1) : {}"".format(result[ :])))
La valeur de la somme carrée est simplement imprimée sous la forme :
>>> print("Somme des carrés(in process p1) : {}"".format(square_sum.value)))
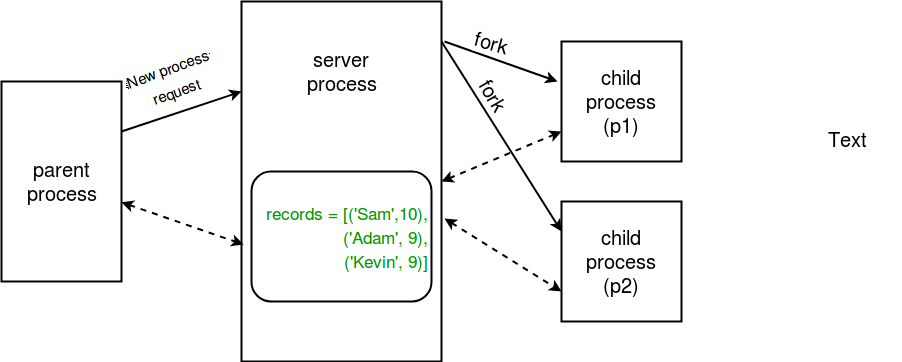
Processus serveur¶
Chaque fois qu’un programme python démarre, un processus serveur est également démarré. A partir de là, chaque fois qu’un nouveau processus est nécessaire, le processus parent se connecte au serveur et lui demande de forker un nouveau processus. Un processus serveur peut contenir des objets Python et permet à d’autres processus de les manipuler à l’aide de proxies. Le module multiprocesseur fournit une classe Manager qui contrôle un processus serveur. Ainsi, les gestionnaires fournissent un moyen de créer des données qui peuvent être partagées entre différents processus. Les gestionnaires de processus de serveur sont plus flexibles que l’utilisation d’objets de mémoire partagée car ils peuvent être faits pour supporter des types d’objets arbitraires comme des listes, des dictionnaires, des files d’attente, des valeurs, des tableaux, etc. De plus, un seul gestionnaire peut être partagé par des processus sur différents ordinateurs sur un réseau. Ils sont cependant plus lents que l’utilisation de la mémoire partagée.
>>> import multiprocessing
>>>
>>> def print_records(records):
>>> """
>>> function to print record(tuples) in records(list)
>>> """
>>> for record in records:
>>> print("Name: {0}\nScore: {1}\n".format(record[0], record[1]))
>>>
>>> def insert_record(record, records):
>>> """
>>> function to add a new record to records(list)
>>> """
>>> records.append(record)
>>> print("New record added!\n")
>>>
>>> if __name__ == '__main__':
>>> with multiprocessing.Manager() as manager:
>>> # creating a list in server process memory
>>> records = manager.list([('Sam', 10), ('Adam', 9), ('Kevin',9)])
>>> # new record to be inserted in records
>>> new_record = ('Jeff', 8)
>>>
>>> # creating new processes
>>> p1 = multiprocessing.Process(target=insert_record, args=(new_record, records))
>>> p2 = multiprocessing.Process(target=print_records, args=(records,))
>>>
>>> # running process p1 to insert new record
>>> p1.start()
>>> p1.join()
>>>
>>> # running process p2 to print records
>>> p2.start()
>>> p2.join()
Essayons de comprendre le morceau de code ci-dessus.
Tout d’abord, nous créons un objet manager à l’aide de :
>>> with multiprocessing.Manager() as manager :
Toutes les lignes sous avec bloc d’instruction sont sous le champ d’application de l’objet manager.
Ensuite, nous créons une liste d’enregistrements dans la mémoire de processus du serveur en utilisant :
>>> records = manager.list([(('Sam', 10), ('Adam', 9), ('Kevin',9)]))
De même, vous pouvez créer un dictionnaire avec la méthode manager.dict.
Enfin, nous créons des processus p1 (pour insérer un nouvel enregistrement dans la liste des enregistrements) et p2 (pour imprimer les enregistrements) et nous les exécutons en passant les enregistrements comme l’un des arguments.
Class Pipe&Queue¶
L’utilisation efficace de plusieurs processus exige habituellement une certaine communication entre eux, de sorte que le travail peut être divisé et que les résultats peuvent être agrégés. Le multi-traitement prend en charge deux types de canaux de communication entre les processus :
Queue;
Pipe.
Queue¶
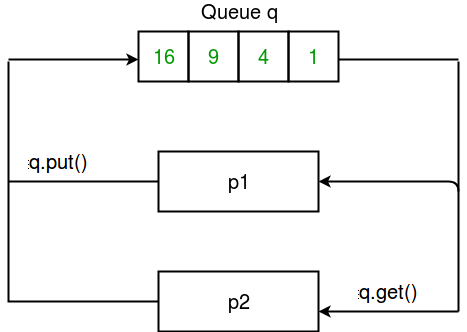
Une façon simple de communiquer entre processus est d’utiliser une file d’attente pour faire passer des messages dans les deux sens. Tout objet Python peut passer par une file d’attente. Note : La classe multiprocessing.Queue est un clone proche de queue.Queue.
Considérons l’exemple de programme donné ci-dessous :
>>> import multiprocessing
>>>
>>> def square_list(mylist, q):
>>> """
>>> function to square a given list
>>> """
>>> # append squares of mylist to queue
>>> for num in mylist:
>>> q.put(num * num)
>>>
>>> def print_queue(q):
>>> """
>>> function to print queue elements
>>> """
>>> print("Queue elements:")
>>> while not q.empty():
>>> print(q.get())
>>> print("Queue is now empty!")
>>>
>>> if __name__ == "__main__":
>>> # input list
>>> mylist = [1,2,3,4]
>>>
>>> # creating multiprocessing Queue
>>> q = multiprocessing.Queue()
>>>
>>> # creating new processes
>>> p1 = multiprocessing.Process(target=square_list, args=(mylist, q))
>>> p2 = multiprocessing.Process(target=print_queue, args=(q,))
>>>
>>> # running process p1 to square list
>>> p1.start()
>>> p1.join()
>>>
>>> # running process p2 to get queue elements
>>> p2.start()
>>> p2.join()
Essayons de comprendre le code ci-dessus étape par étape.
Tout d’abord, nous créons une file d’attente multiprocessing en utilisant :
>>> q = multiprocessing.Queue()
Ensuite, nous passons la file d’attente vide q à la fonction square_list à travers le processus p1. Les éléments sont insérés dans la file d’attente en utilisant la méthode put.
>>> q.put(num * num * num)
Afin d’imprimer les éléments de file d’attente, nous utilisons la méthode get jusqu’à ce que la file d’attente soit vide.
>>> while not q.empty():
>>> print(q.get()))
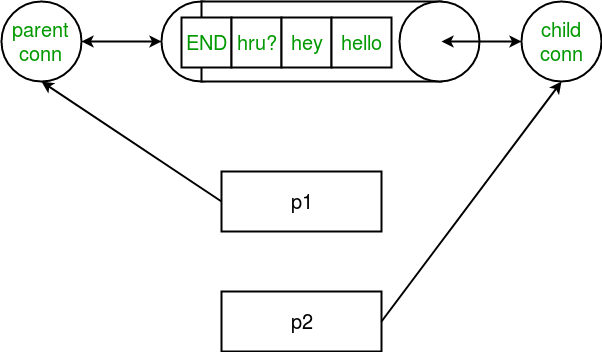
Pipe¶
Un Pipe ne peut avoir que deux points d’extrémité. Par conséquent, il est préférable à la file d’attente lorsque seule une communication bidirectionnelle est requise. Le module multiprocesseur fournit la fonction Pipe() qui renvoie une paire d’objets de connexion reliés par un tuyau. Les deux objets de connexion renvoyés par Pipe() représentent les deux extrémités du tuyau. Chaque objet de connexion a des méthodes send() et recv() (entre autres). Considérons le programme ci-dessous :
>>> import multiprocessing
>>>
>>> def sender(conn, msgs):
>>> """
>>> function to send messages to other end of pipe
>>> """
>>> for msg in msgs:
>>> conn.send(msg)
>>> print("Sent the message: {}".format(msg))
>>> conn.close()
>>>
>>> def receiver(conn):
>>> """
>>> function to print the messages received from other
>>> end of pipe
>>> """
>>> while 1:
>>> msg = conn.recv()
>>> if msg == "END":
>>> break
>>> print("Received the message: {}".format(msg))
>>>
>>> if __name__ == "__main__":
>>> # messages to be sent
>>> msgs = ["hello", "hey", "hru?", "END"]
>>>
>>> # creating a pipe
>>> parent_conn, child_conn = multiprocessing.Pipe()
>>>
>>> # creating new processes
>>> p1 = multiprocessing.Process(target=sender, args=(parent_conn,msgs))
>>> p2 = multiprocessing.Process(target=receiver, args=(child_conn,))
>>>
>>> # running processes
>>> p1.start()
>>> p2.start()
>>>
>>> # wait until processes finish
>>> p1.join()
>>> p2.join()
Essayons de comprendre le code ci-dessus.
Un tuyau a été créé simplement en utilisant :
>>> parent_conn, child_conn = multiprocessing.Pipe()
La fonction renvoie deux objets de connexion pour les deux extrémités du tuyau.
Le message est envoyé d’une extrémité du tuyau à l’autre en utilisant la méthode d’envoi.
>>> conn.send(msg)
Pour recevoir des messages à une extrémité d’un tuyau, nous utilisons la méthode recv.
>>> msg = conn.recv()
Dans le programme ci-dessus, nous envoyons une liste de messages d’un bout à l’autre. A l’autre extrémité, nous lisons les messages jusqu’à ce que nous recevions le message « END ».
Note : Les données d’un tuyau peuvent être corrompues si deux processus (ou filetages) tentent de lire ou d’écrire à la même extrémité du tuyau en même temps. Bien sûr, il n’y a pas de risque de corruption par des processus utilisant différentes extrémités du tuyau en même temps. Notez également que les files d’attente font une synchronisation correcte entre les processus, au détriment d’une plus grande complexité. Par conséquent, on dit que les files d’attente sont sans danger pour les threads et les processus !
Class Lock¶
Synchronisation entre les processus¶
La synchronisation des processus est définie comme un mécanisme qui garantit que deux ou plusieurs processus simultanés n’exécutent pas simultanément un segment de programme particulier connu sous le nom de section critique.
La section critique fait référence aux parties du programme où l’on accède à la ressource partagée.
Par exemple, dans le diagramme ci-dessous, 3 processus essaient d’accéder à la ressource partagée ou à la section critique en même temps.

Les accès simultanés à des ressources partagées peuvent conduire à des conditions de compétitions.
Le module multiprocessing fournit une classe Lock pour traiter les conditions de compétition. Lock est implémenté à l’aide d’un objet Semaphore fourni par le système d’exploitation.
Un sémaphore est un objet de synchronisation qui contrôle l’accès par plusieurs processus à une ressource commune dans un environnement de programmation parallèle. C’est simplement une valeur à un endroit désigné dans le stockage du système d’exploitation (ou du noyau) que chaque processus peut vérifier et ensuite changer. Selon la valeur trouvée, le processus peut utiliser la ressource ou s’apercevra qu’elle est déjà utilisée et doit attendre un certain temps avant de réessayer. Les sémaphores peuvent être binaires (0 ou 1) ou avoir des valeurs supplémentaires. Typiquement, un processus utilisant des sémaphores vérifie la valeur et, s’il utilise la ressource, change la valeur pour refléter ceci afin que les utilisateurs de sémaphores ultérieurs sachent qu’ils doivent attendre.
Considérons le programme suivant:
>>> # Python program to illustrate
>>> # the concept of race condition
>>> # in multiprocessing
>>> import multiprocessing
>>>
>>> # function to withdraw from account
>>> def withdraw(balance):
>>> for _ in range(10000):
>>> balance.value = balance.value - 1
>>>
>>> # function to deposit to account
>>> def deposit(balance):
>>> for _ in range(10000):
>>> balance.value = balance.value + 1
>>>
>>> def perform_transactions():
>>>
>>> # initial balance (in shared memory)
>>> balance = multiprocessing.Value('i', 100)
>>>
>>> # creating new processes
>>> p1 = multiprocessing.Process(target=withdraw, args=(balance,))
>>> p2 = multiprocessing.Process(target=deposit, args=(balance,))
>>>
>>> # starting processes
>>> p1.start()
>>> p2.start()
>>>
>>> # wait until processes are finished
>>> p1.join()
>>> p2.join()
>>>
>>> # print final balance
>>> print("Final balance = {}".format(balance.value))
>>>
>>> if __name__ == "__main__":
>>> for _ in range(10):
>>>
>>> # perform same transaction process 10 times
>>> perform_transactions()
Dans le programme ci-dessus, 10000 retraits et 10000 dépôts sont effectués avec un solde initial de 100. Le solde final attendu est de 100, mais ce que nous obtenons avec les 10 itérations de la fonction perform_transactions, ce sont des valeurs différentes.
Cela se produit en raison de l’accès simultané des processus à la balance des données partagées. Cette imprévisibilité de la valeur d’équilibre n’est rien d’autre qu’une condition de compétition.
Résolvons le problème :
>>> # Python program to illustrate
>>> # the concept of locks
>>> # in multiprocessing
>>> import multiprocessing
>>>
>>> # function to withdraw from account
>>> def withdraw(balance, lock):
>>> for _ in range(10000):
>>> lock.acquire()
>>> balance.value = balance.value - 1
>>> lock.release()
>>>
>>> # function to deposit to account
>>> def deposit(balance, lock):
>>> for _ in range(10000):
>>> lock.acquire()
>>> balance.value = balance.value + 1
>>> lock.release()
>>>
>>> def perform_transactions():
>>>
>>> # initial balance (in shared memory)
>>> balance = multiprocessing.Value('i', 100)
>>>
>>> # creating a lock object
>>> lock = multiprocessing.Lock()
>>>
>>> # creating new processes
>>> p1 = multiprocessing.Process(target=withdraw, args=(balance,lock))
>>> p2 = multiprocessing.Process(target=deposit, args=(balance,lock))
>>>
>>> # starting processes
>>> p1.start()
>>> p2.start()
>>>
>>> # wait until processes are finished
>>> p1.join()
>>> p2.join()
>>>
>>> # print final balance
>>> print("Final balance = {}".format(balance.value))
>>>
>>> if __name__ == "__main__":
>>> for _ in range(10):
>>>
>>> # perform same transaction process 10 times
>>> perform_transactions()
>>>
>>>
Essayons de comprendre le code ci-dessus étape par étape.
Tout d’abord, un objet Lock est créé à l’aide de :
>>> lock = multiprocessing.Lock()
Ensuite, lock est passé comme argument de fonction cible :
>>> p1 = multitraitement.process(target=withdraw, args=(balance,lock))
>>> p2 = multiprocessing.process(target=deposit, args=(balance,lock))
Dans la section critique de la fonction cible, nous appliquons lock en utilisant la méthode lock.acquire(). Dès qu’un verrou est acquis, aucun autre processus ne peut accéder à la section critique jusqu’à ce que le verrou soit libéré en utilisant la méthode lock.release().
>>> lock.acquire()
>>> balance.value = balance.value - 1
>>> lock.release()
Comme vous pouvez le voir dans les résultats, le solde final est de 100 à chaque fois (ce qui est le résultat final attendu).
Class Pool¶
Mise en commun entre les processus¶
Considérons un programme simple pour calculer les carrés de nombres dans une liste donnée.
>>> # Python program to find
>>> # squares of numbers in a given list
>>> def square(n):
>>> return (n*n)
>>>
>>> if __name__ == "__main__":
>>>
>>> # input list
>>> mylist = [1,2,3,4,5]
>>>
>>> # empty list to store result
>>> result = []
>>>
>>> for num in mylist:
>>> result.append(square(num))
>>>
>>> print(result)
Dans un système multi-noyau/multi-processeur, considérons le diagramme ci-dessous pour comprendre comment le programme ci-dessus fonctionnera :
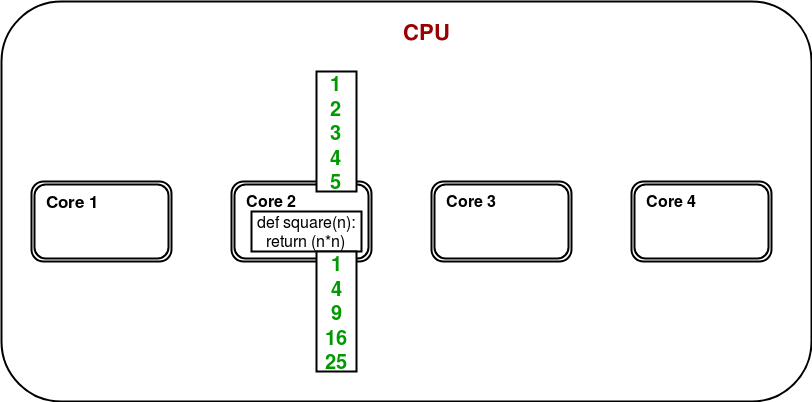
Un seul des noyaux est utilisé pour l’exécution du programme et il est tout à fait possible que d’autres noyaux restent inactifs.
Afin d’utiliser tous les coeurs, le module multiprocessing fournit une classe Pool. La classe Pool représente un pool de processus de tâches. Il a des méthodes qui permettent de décharger les tâches sur les processus de différentes manières. Considérons le diagramme ci-dessous :
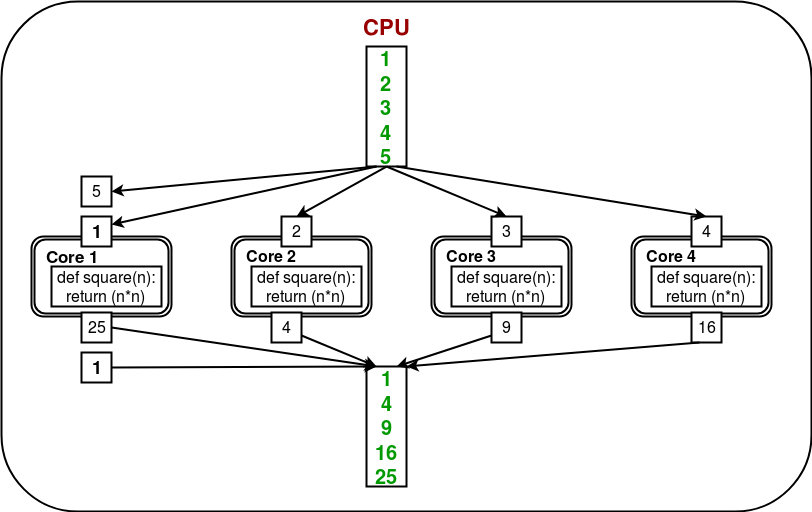
Ici, la tâche est déchargée/répartie entre les coeurs / processus automatiquement par objet Pool. L’utilisateur n’a pas besoin de se soucier de créer des processus explicitement.
>>> # Python program to understand
>>> # the concept of pool
>>> import multiprocessing
>>> import os
>>>
>>> def square(n):
>>> print("Worker process id for {0}: {1}".format(n, os.getpid()))
>>> return (n*n)
>>>
>>> if __name__ == "__main__":
>>> # input list
>>> mylist = [1,2,3,4,5]
>>>
>>> # creating a pool object
>>> p = multiprocessing.Pool()
>>>
>>> # map list to target function
>>> result = p.map(square, mylist)
>>>
>>> print(result)
Essayons de comprendre pas à pas le code ci-dessus :
Nous créons un objet Pool à l’aide de :
>>> p = multiprocessing.Pool()
Il y a quelques arguments pour obtenir plus de contrôle sur le chargement de la tâche. Ceux-ci sont :
processes : spécifie le nombre de processus;
maxtasksperchild : spécifie le nombre maximum de tâches à assigner par enfant;
Tous les processus d’un pool peuvent être initialisés à l’aide de ces arguments :
initializer : spécifie une fonction d’initialisation pour les processus;
initargs : arguments à passer à l’initialisateur.
Maintenant, pour effectuer une tâche, nous devons la mettre en correspondance avec une fonction. Dans l’exemple ci-dessus, nous mappons mylist à la fonction square. En conséquence, le contenu de mylist et la définition du carré seront distribués entre les noyaux.
>>> result = p.map(square, mylist)
Une fois que tous les processus ont terminé leur tâche, une liste est retournée avec le résultat final.